鄂州市网站建设_网站建设公司_服务器维护_seo优化
一、查漏补缺、熟能生巧:
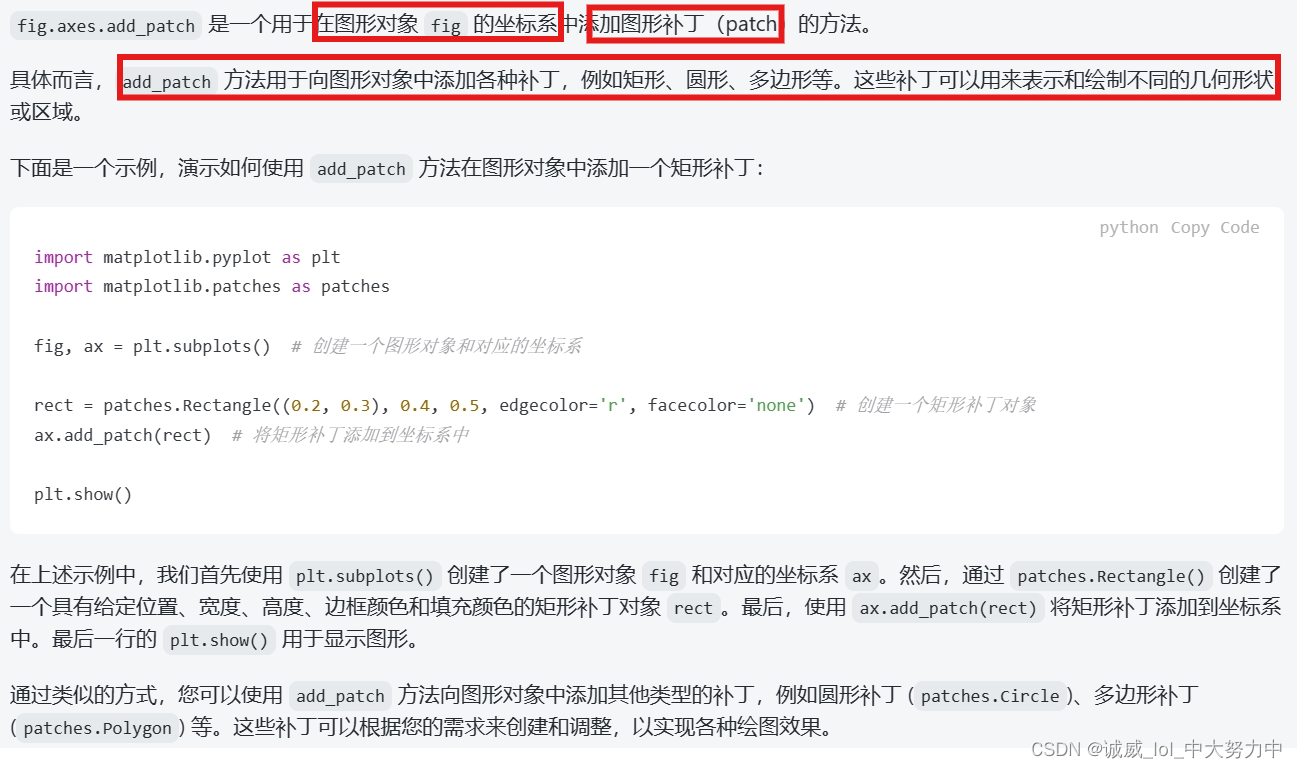
1.关于fix.axis.add_patch在原来图像的坐标系同添加 边框的函数的使用:
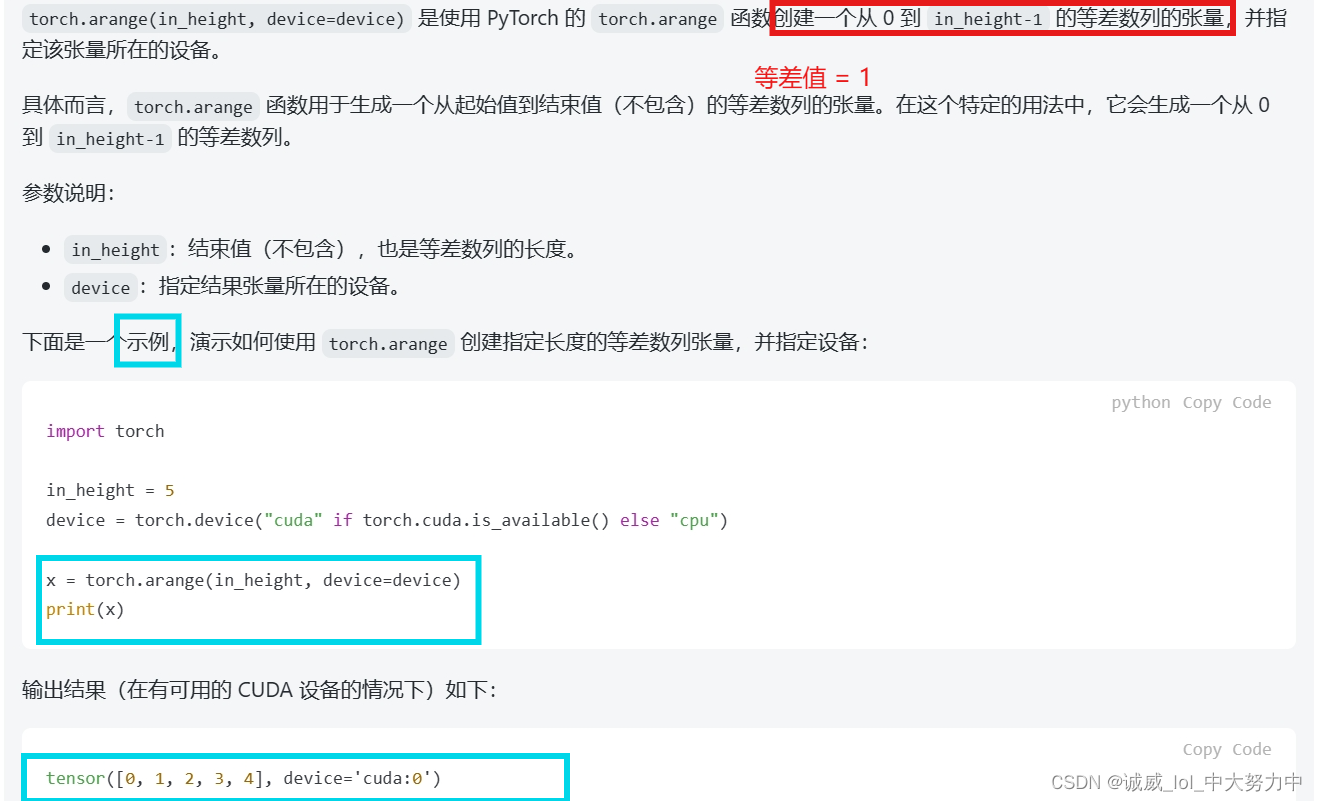
2.torch.arange( h , device)生成tensor的等差数组:
3.torch.T()就是transpose转置操作的函数咯:

4.torch.repeat操作,用于将单个结构重复多次,从而产生更大的结构:

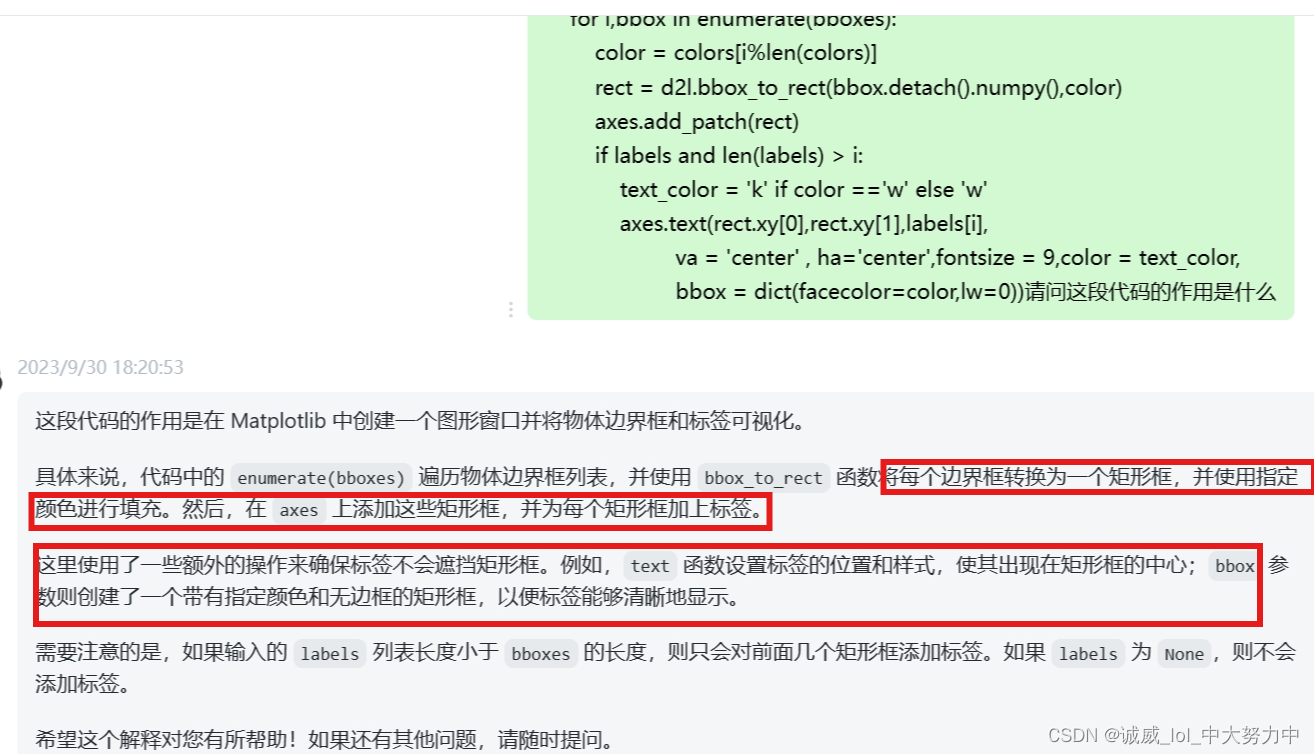
5.添加矩形框的代码的诡异之处
6.创建初始的anchors锚框 和 bbox真实边框的映射关系

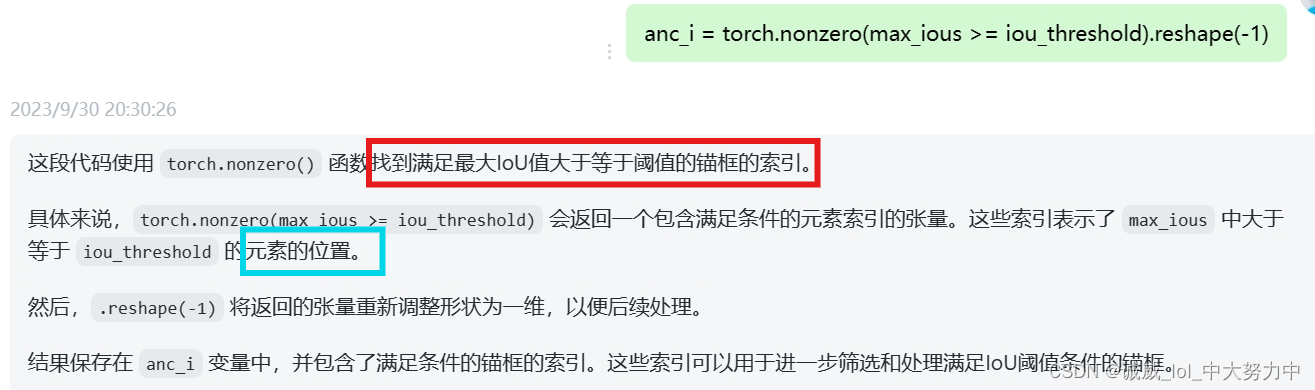
7.torch.nonzero一般就是用于这种判断bool类型的过程中
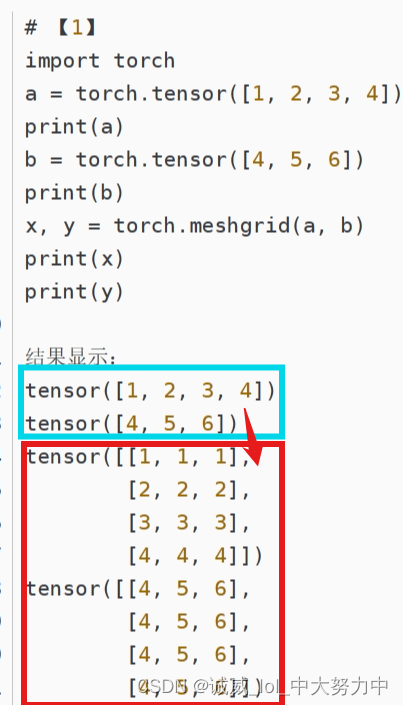
8.torch.meshgrid()函数的作用:

具体参考这一篇文章,写得非常清晰:
http://t.csdnimg.cn/5lBJT
9.torch.cat() 和 torch.stack()这2个拼接函数用得还是很多的,所以具体可以看这篇文章:
http://t.csdnimg.cn/iMC1M
10.torch.full()函数的用法:


11.torch.repeat()的函数的具体分析过程:
(1)首先,在最初的时候,anchor到gt的映射记录只是1个n的数据的向量
通过这个>=的比较,得到(n*1)的掩码数据,
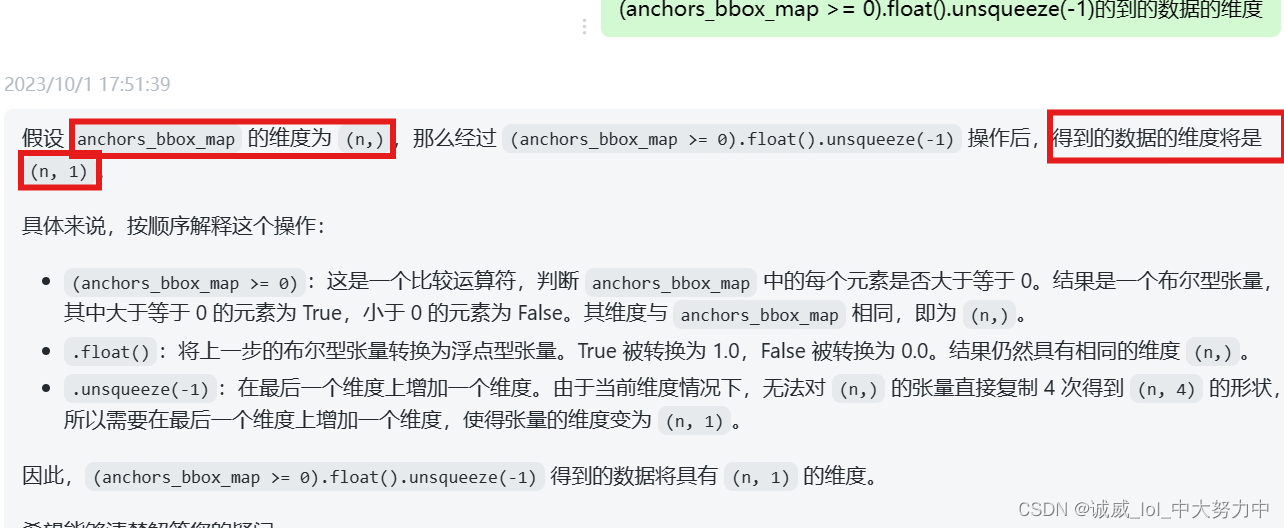
(2)然后,通过调用torch.repeat(1,4)在第一维重复4次,得到n*4的掩码数据:

12.巧妙的利用torch.arange()和 unique函数,实现提取出背景anchor的下标:

二、代码的理解阅读:
特别感谢chatGPT对于这个部分的解读:
这个jaccard真的一语道破

感谢chatGPT对于这个offset计算的讲解:

