临沂市网站建设_网站建设公司_网站建设_seo优化
写在最后
经过将近一周时间的框架收集、学习、实验、编码、测试市面上常见的ORM框架,过程中拜读了很多作者的博文、样例,学习很多收获很多。
重新梳理下整理的框架:mybatis-plus、lazy、sqltoy、mybatis-flex、easy-query、mybatis-mp、jpa、dbvisitor、beetlsql
下面从一下几点出发作出总结
- 文档方面:学习过程中mybatis-plus、jpa 提供的文档资料是比较全和晚上,经得住市场的考验
- 技术方面:beetlsql、easy-query、mybatis系列 三类框架都已经支持spring 和solon生态 其技术架构设计可以推荐大家学习
- 并发方面:jpa、db_visitor 还需要开发时候深度优化处理
- 大数据存储方面: Lazy 具有一定优势
大数据查询方面:sqltoy反射处理的比较优秀
以上是个人整理的观点,如果大家有不同的想法和意见可以在gitee或者个人博客留言CSDN
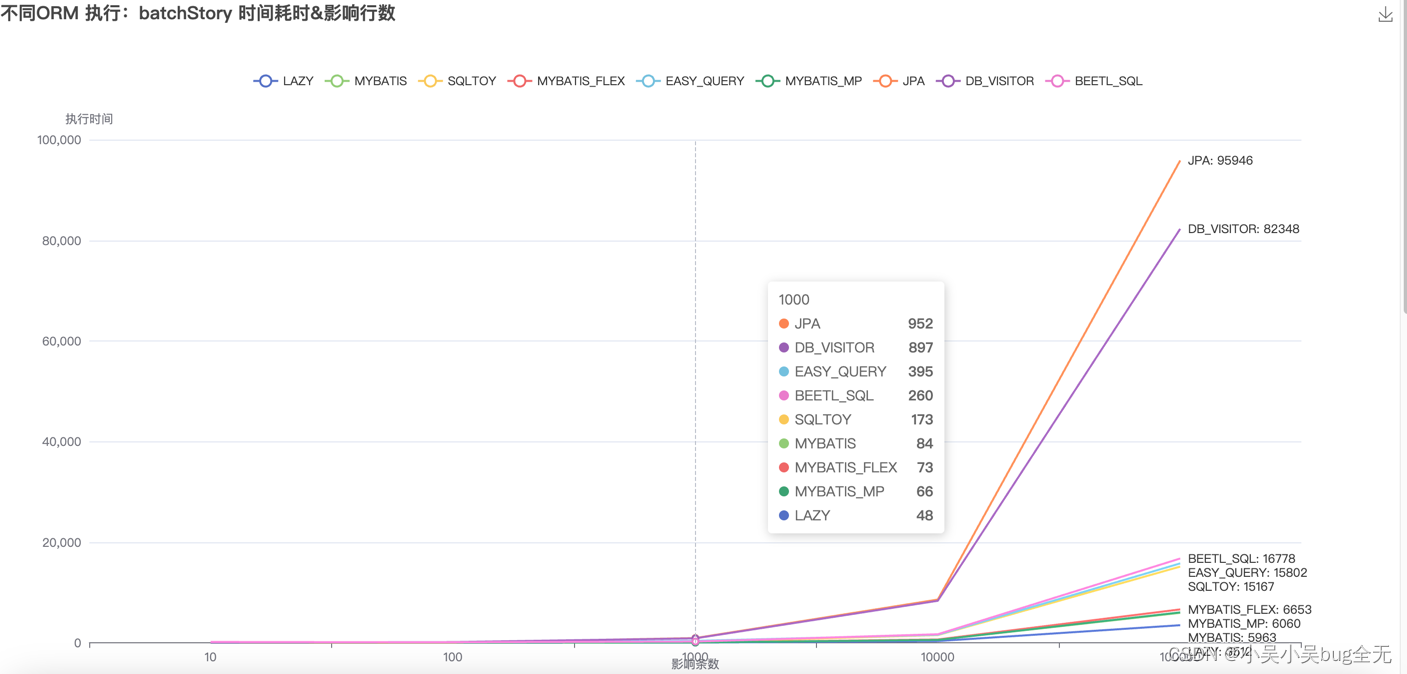
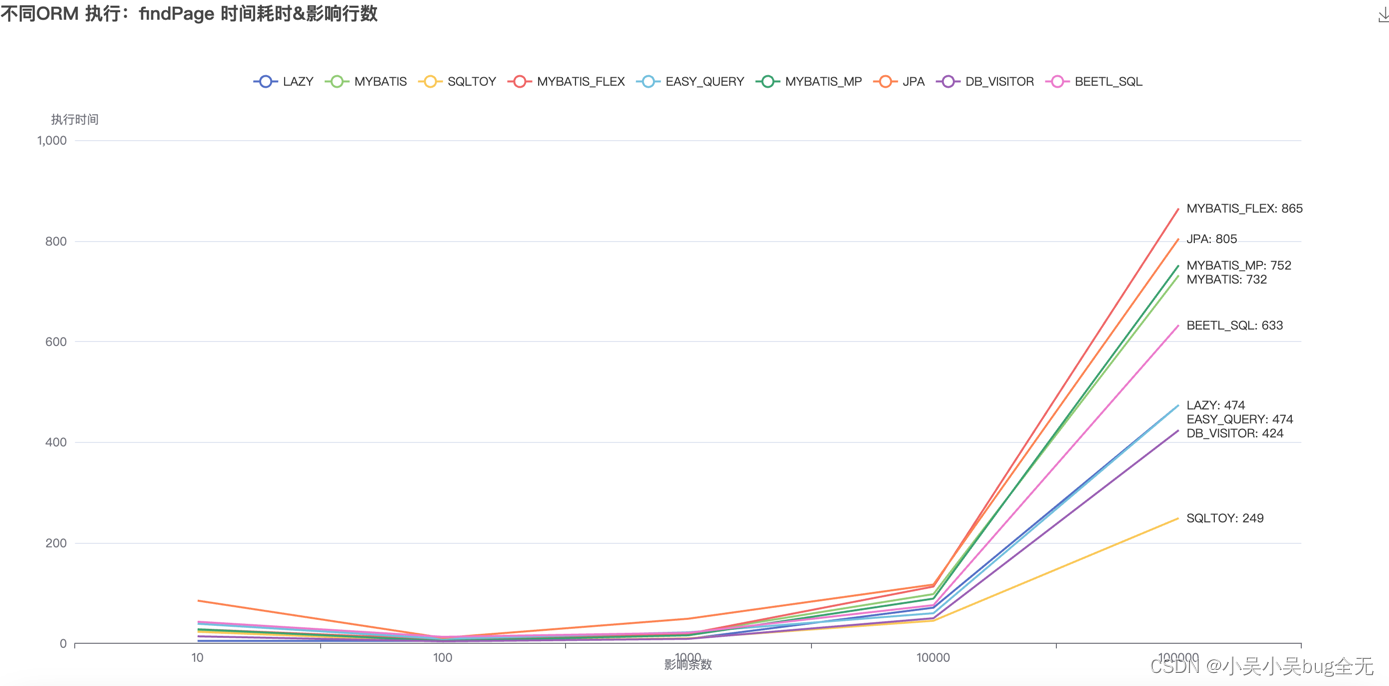
细节数据对比(一万以内基本相差不大)
- 细节数据对比,数据属于并发行测试数据,如果测试总数是一百,那么会执行一百次batchStory,一百次findPage 每次执行的条数在之前数据的基础上+1
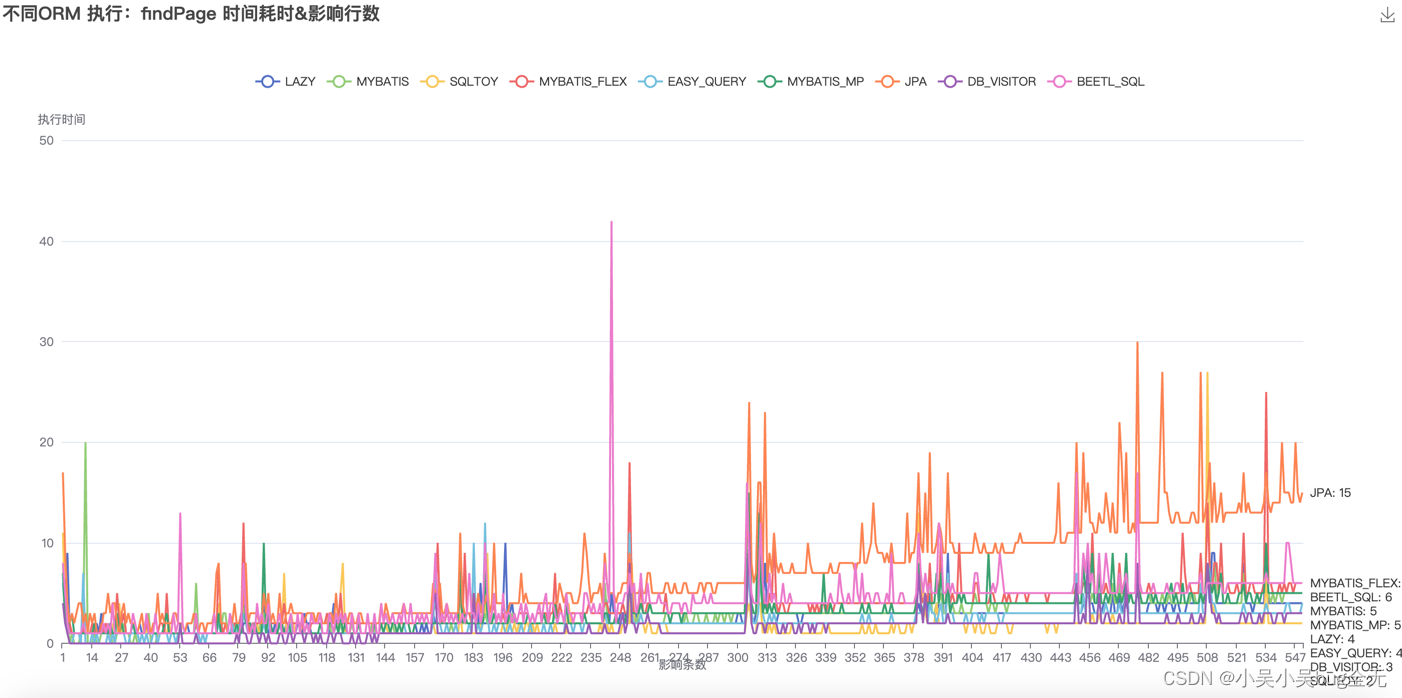
从形成的折线图看(具体趋势看排名与测试结果)
- 存储性能对比: lazy、mybatis-flex、mybatis-mp、mybatis、easy-query、sqltoy、beetlSql 更适合并发性数据存储。jpa、db_visitor 处理耗时较长
- 分页查询性能对比: lazy、mybatis-flex、mybatis-mp、mybatis、easy-query、sqltoy、db_visitor、beetlSql 都比较稳定。jpa 处理时间明显起伏
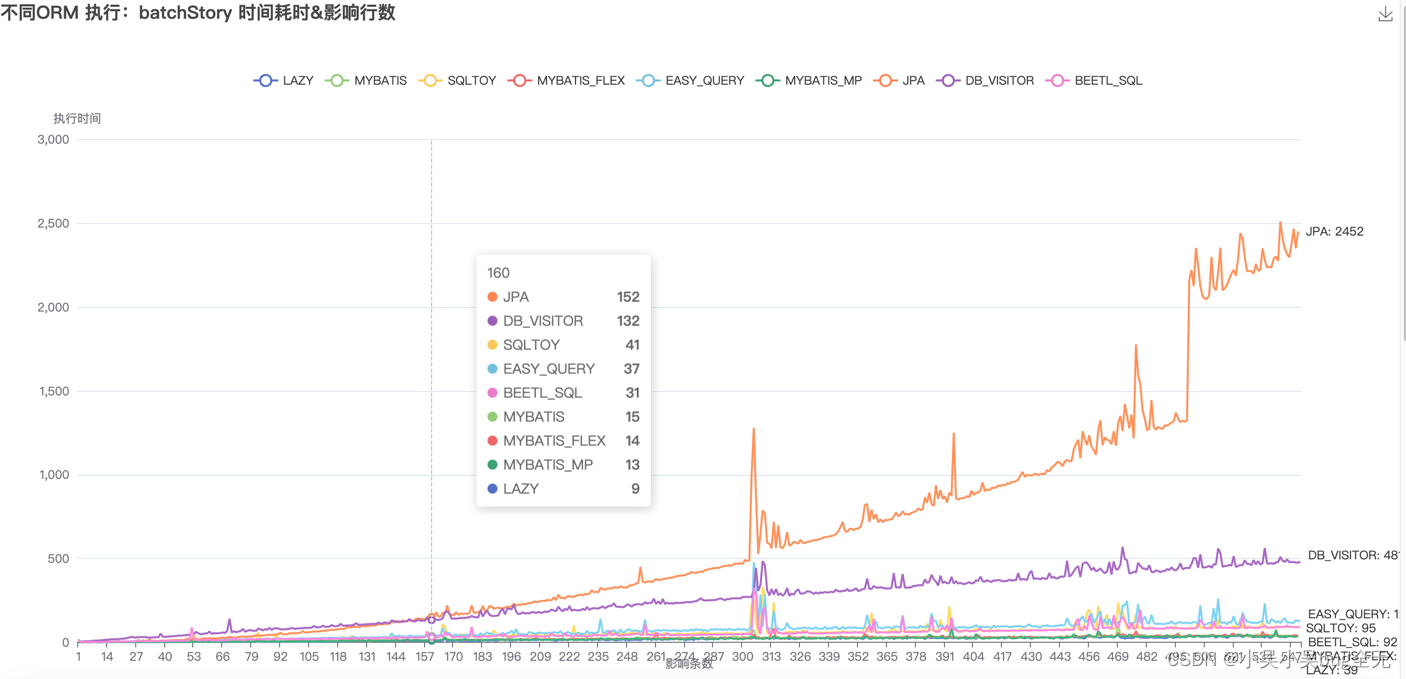
批量保存:
- 一万条数据以内 lazy、mybatis-flex、mybatis-mp、mybatis、easy-query、sqltoy、beetlSql、jpa、db_visitor 性能趋于一致
- 十万数据时,处理时间由快到慢依次是: lazy、mybatis-flex、mybatis-mp、mybatis、easy-query、sqltoy、beetlSql、db_visitor、jpa,其中 db_visitor、jpa 处理时间明显起伏
分页查询:
- 一万条数据以内 几款ORM均保持在200毫秒内
- 十万数据时,处理时间由快到慢依次是: sqltoy、db_visitor、easy-query、lazy、beetlSql、mybatis、mybatis-mp、jpa、mybatis-flex
快速数据对比(大数据曲线图)