南投县网站建设_网站建设公司_Photoshop_seo优化
文章目录
- 一、Service 存在的意义
- 二、Pod与Service的关系
- 三、Service定义与创建
- 四、Service三种常用类型
- 五、Service代理模式
- 六、切换Service代理模式
- 七、service总体工作流程
- 八、kube-proxy ipvs和iptables的异同
- 九、Service DNS名称
一、Service 存在的意义
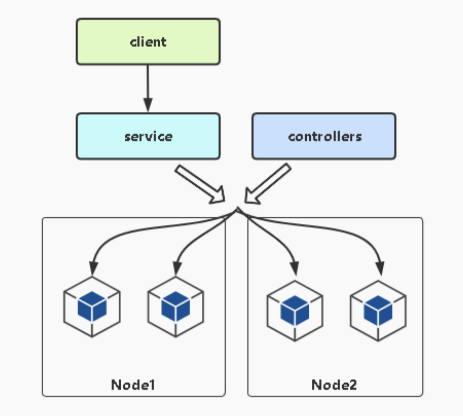
service的引入主要是为了解决pod的动态变化,提供统一访问入口:
- 防止Pod失联,找到提供同一个服务的pod(服务发现)
- 定义一组pod的访问策略(负载均衡)
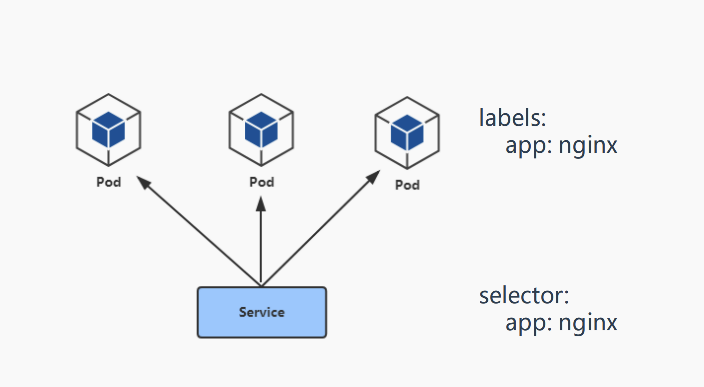
二、Pod与Service的关系
- service通过标签关联一组pod(可通过kubectl get ep查看)
- service为一组pod提供负载均衡的能力
[root@k8s-master ~]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.77.11:6443 163d
web3 10.244.36.67:80,10.244.36.74:80,10.244.36.92:80 5d2h
三、Service定义与创建
示例一:
1.创建一个service
apiVersion: v1
kind: Service
metadata:name: weblabels:app: web
spec:type: ClusterIPports:- protocol: TCP#Service端口,用于集群内部其它pod访问的端口port: 80#容器中服务运行的端口,可以理解为是容器内应用的端口;例如nginx 80、tomcat 8080、mysql 3306targetPort: 9376selector:#指定关联Pod的标签app: web
2.运行此yaml并查看创建的service
[root@k8s-master ~]# kubectl apply -f service.yaml
service/web created
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web ClusterIP 10.108.117.153 <none> 80/TCP 26s
示例二:
1.多端口Service定义
- 对于某些服务,需要公开多个端口,Service也需要配置多个端口定义,通过端口名称区分;
apiVersion: v1
kind: Service
metadata:name: web2labels:app: web
spec:type: ClusterIPports:- name: httpprotocol: TCP#Service端口,用于集群内部其它pod访问的端口port: 80#容器中服务运行的端口,可以理解为是容器内应用的端口;例如nginx 80、tomcat 8080、mysql 3306targetPort: 80- name: httpsprotocol: TCPport: 443targetPort: 443selector:#指定关联Pod的标签app: web
2.运行此yaml并查看创建的service
[root@k8s-master ~]# kubectl apply -f service-mutil.yaml
service/web2 created
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web2 ClusterIP 10.107.141.88 <none> 80/TCP,443/TCP 5s
四、Service三种常用类型
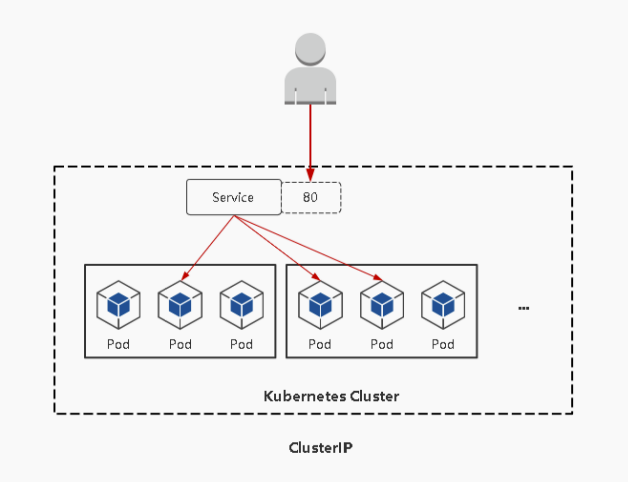
ClusterIP:默认,分配一个稳定的IP地址,即VIP,只能在集群内部访问;
示例:
...
spec:#指定Service的类型type: ClusterIPports:- protocol: TCP#Service端口,用于集群内部其它pod访问的端口port: 80#容器中服务运行的端口,可以理解为是容器内应用的端口;例如nginx 80、tomcat 8080、mysql 3306targetPort: 80selector:app: web
k8s集群中应用之间的访问使用的就是Cluster IP
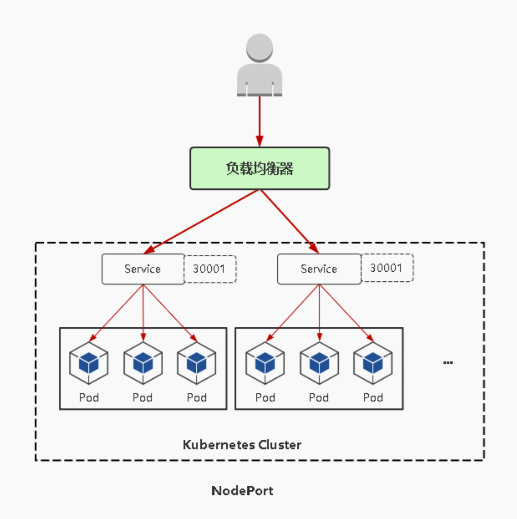
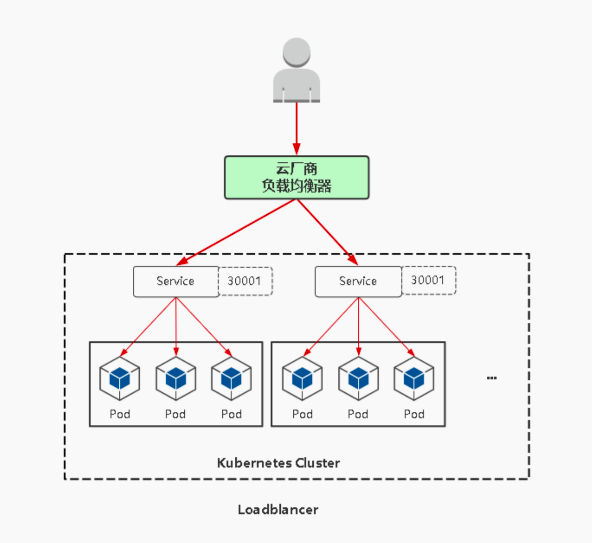
NodePort:会在每台节点上启用一个端口来暴露服务(接受用户流量),可以在集群外部访问,同时也会分配一个稳定的内部集群IP地址;
访问地址:<任意NodeIP>:
默认Nodeport端口范围:30000-32767
在实际情况下,对用户暴露的只会有一个IP和端口,那这么多台Node该使用哪台让用户访问呢?
这时就需要在所有Node前面加一个公网负载均衡器来为项目提供统一访问入口了
示例:
spec:#指定Service的类型type: NodePortports:- name: httpprotocol: TCP#Service端口,用于集群内部其它pod访问的端口port: 80#容器中服务运行的端口,可以理解为是容器内应用的端口;例如nginx 80、tomcat 8080、mysql 3306targetPort: 80#暴露集群外部访问的端口,默认的话是在30000-32767之间随机的nodePort: 30009selector:#指定关联Pod的标签app: web
运行此yaml后验证
[root@k8s-master ~]# kubectl apply -f service-nodeport.yaml
service/web3 created
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 53d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 64d
web3 NodePort 10.97.249.155 <none> 80:30009/TCP 3s
#可以去每个节点上查看NodePort端口,都是有被宿主机监听的
[root@k8s-master ~]# ss -unptl | grep 30009
tcp LISTEN 0 128 *:30009 *:* users:(("kube-proxy",pid=3729,fd=20))然后浏览器访问任意节点IP:30009(NodePort端口)
LoadBalancer:与NodePort类似,在每个节点上启用一个端口来暴露服务;除此之外,kubernetes会请求底层云平台(例如阿里云、腾讯云、AWS等)上的负载均衡器,将每个Node([NodeIP]:[NodePort])作为后端添加进去。
tips:实现nginx自动添加配置文件可以使用consul + confd技术方案;
示例:
阿里云ACK LoadBalancer使用方法
五、Service代理模式
官方地址:https://kubernetes.io/docs/reference/networking/virtual-ips/
service的底层实现主要由iptables和ipvs两种网络模式来决定如何转发流量
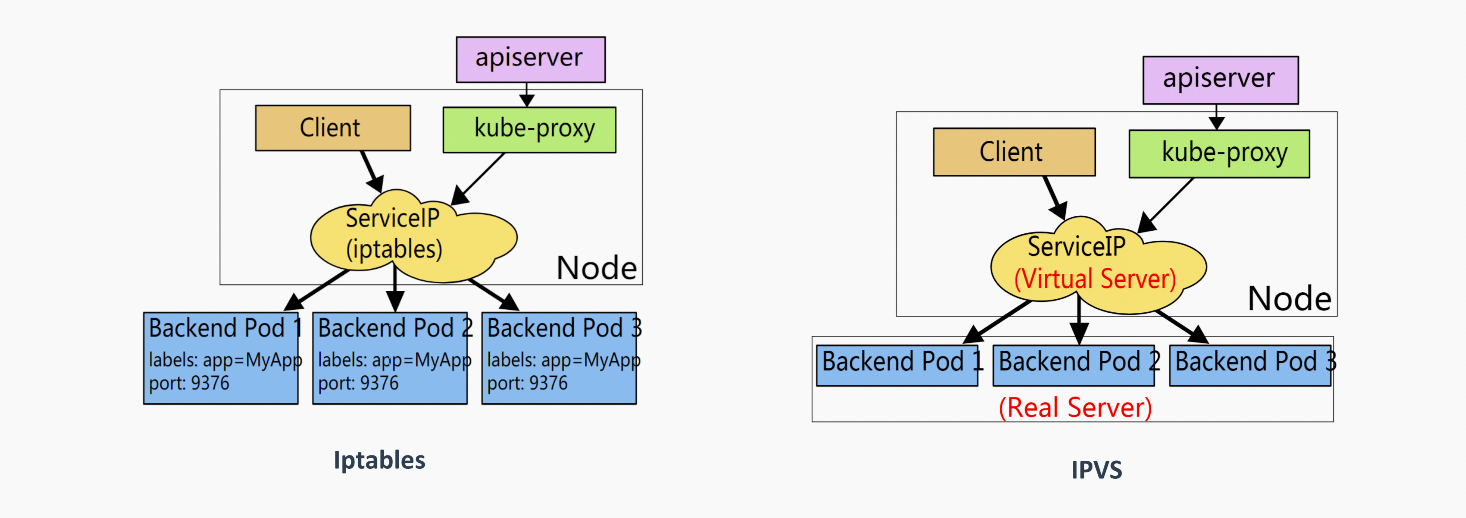
- iptables模式:
如上图,当客户端去访问servcie时 iptables会帮我们将请求转发至后端的pod上,注意iptables是有相对应的规则的,这些规则就是kube-proxy来进行维护的 service本就是一种抽象的资源 它不具备任何转发的能力; - ipvs代理模式:大致上跟iptables模式一致,当访问servcie时,ipvs会将请求转发至后端的pod,也是kube-proxy来进行维护转发规则的,所以这是不同的转发机制来实现的数据包的转发
注意:services不是具体实现转发的,而是背后的iptables/ipvs来实现的;
查看负载均衡规则命令如下:
- iptables模式
iptables-save | grep [SERVICE-NAME] - ipvs模式
ipvsadm -L -n
处理一个请求的流程:
客户端 —> NodePort/ClusterIP(iptables/ipvs负载均衡规则) —> 分布在各个节点Pod
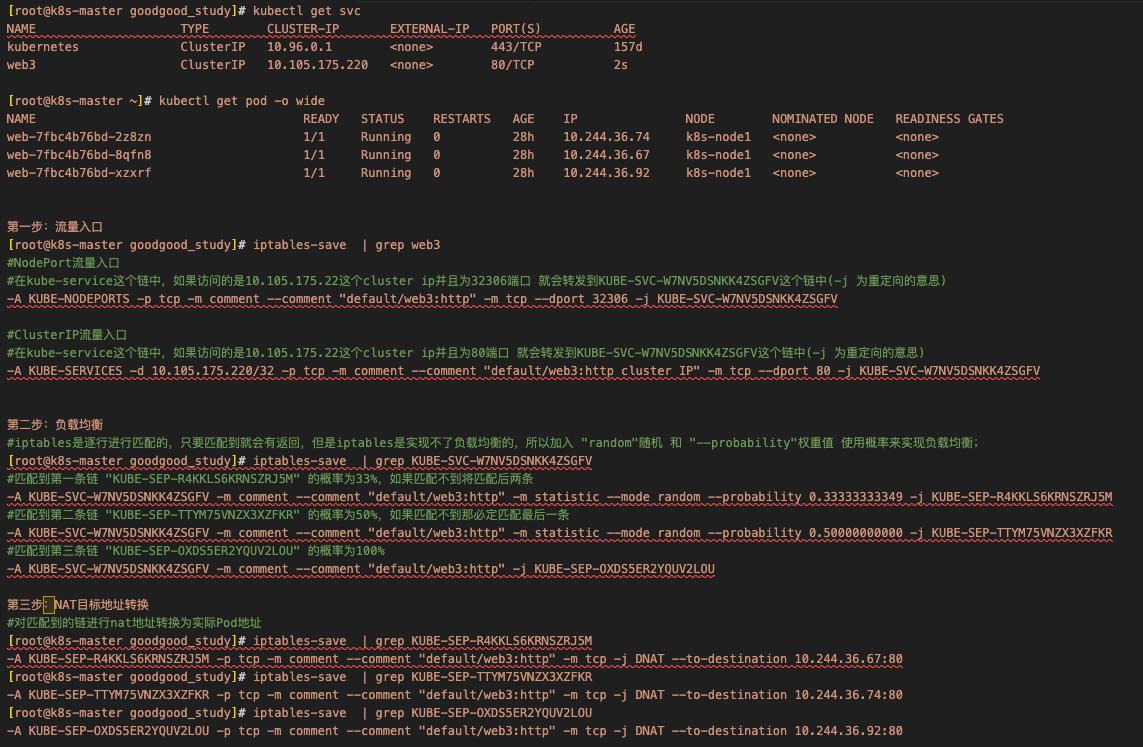
[root@k8s-master goodgood_study]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 157d
web3 ClusterIP 10.105.175.220 <none> 80/TCP 2s[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7fbc4b76bd-2z8zn 1/1 Running 0 28h 10.244.36.74 k8s-node1 <none> <none>
web-7fbc4b76bd-8qfn8 1/1 Running 0 28h 10.244.36.67 k8s-node1 <none> <none>
web-7fbc4b76bd-xzxrf 1/1 Running 0 28h 10.244.36.92 k8s-node1 <none> <none>第一步:流量入口
[root@k8s-master goodgood_study]# iptables-save | grep web3
#NodePort流量入口
#在kube-service这个链中,如果访问的是10.105.175.22这个cluster ip并且为32306端口 就会转发到KUBE-SVC-W7NV5DSNKK4ZSGFV这个链中(-j 为重定向的意思)
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/web3:http" -m tcp --dport 32306 -j KUBE-SVC-W7NV5DSNKK4ZSGFV#ClusterIP流量入口
#在kube-service这个链中,如果访问的是10.105.175.22这个cluster ip并且为80端口 就会转发到KUBE-SVC-W7NV5DSNKK4ZSGFV这个链中(-j 为重定向的意思)
-A KUBE-SERVICES -d 10.105.175.220/32 -p tcp -m comment --comment "default/web3:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-W7NV5DSNKK4ZSGFV第二步:负载均衡
#iptables是逐行进行匹配的,只要匹配到就会有返回,但是iptables是实现不了负载均衡的,所以加入 "random"随机 和 "--probability"权重值 使用概率来实现负载均衡;
[root@k8s-master goodgood_study]# iptables-save | grep KUBE-SVC-W7NV5DSNKK4ZSGFV
#匹配到第一条链 "KUBE-SEP-R4KKLS6KRNSZRJ5M" 的概率为33%,如果匹配不到将匹配后两条
-A KUBE-SVC-W7NV5DSNKK4ZSGFV -m comment --comment "default/web3:http" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-R4KKLS6KRNSZRJ5M
#匹配到第二条链 "KUBE-SEP-TTYM75VNZX3XZFKR" 的概率为50%,如果匹配不到那必定匹配最后一条
-A KUBE-SVC-W7NV5DSNKK4ZSGFV -m comment --comment "default/web3:http" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-TTYM75VNZX3XZFKR
#匹配到第三条链 "KUBE-SEP-OXDS5ER2YQUV2LOU" 的概率为100%
-A KUBE-SVC-W7NV5DSNKK4ZSGFV -m comment --comment "default/web3:http" -j KUBE-SEP-OXDS5ER2YQUV2LOU第三步:NAT目标地址转换
#对匹配到的链进行nat地址转换为实际Pod地址
[root@k8s-master goodgood_study]# iptables-save | grep KUBE-SEP-R4KKLS6KRNSZRJ5M
-A KUBE-SEP-R4KKLS6KRNSZRJ5M -p tcp -m comment --comment "default/web3:http" -m tcp -j DNAT --to-destination 10.244.36.67:80
[root@k8s-master goodgood_study]# iptables-save | grep KUBE-SEP-TTYM75VNZX3XZFKR
-A KUBE-SEP-TTYM75VNZX3XZFKR -p tcp -m comment --comment "default/web3:http" -m tcp -j DNAT --to-destination 10.244.36.74:80
[root@k8s-master goodgood_study]# iptables-save | grep KUBE-SEP-OXDS5ER2YQUV2LOU
-A KUBE-SEP-OXDS5ER2YQUV2LOU -p tcp -m comment --comment "default/web3:http" -m tcp -j DNAT --to-destination 10.244.36.92:80
六、切换Service代理模式
service 默认使用iptables 代理模式
查看当前service使用的代理模式
上面知道了service的转发规则是由kube-proxy维护的 所以可以直接查看kube-proxy的日志即可
kubeadm方式:
[root@k8s-master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
...
kube-proxy-5nthr 1/1 Running 0 159d
kube-proxy-77bv7 1/1 Running 0 158d
kube-proxy-q4tjh 1/1 Running 0 158d
kube-proxy-v7s6z 1/1 Running 0 158d
1.查看任意一个kube-porxy就可以发现使用的是iptables代理模式
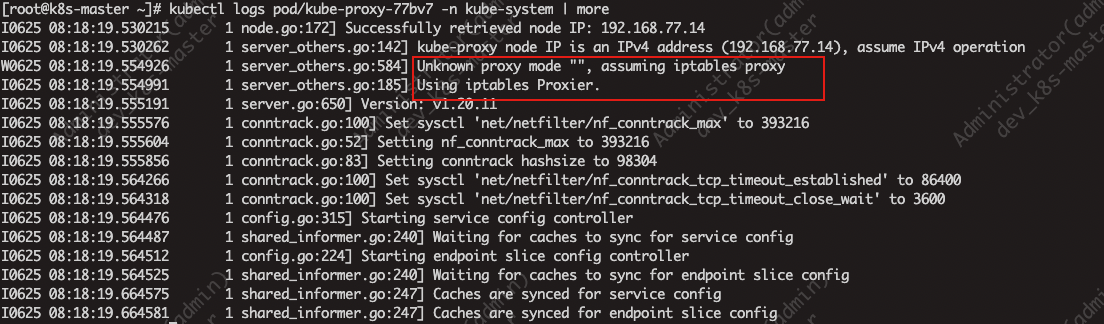
2.切换代理模式就需要修改kube-proxy的configmap
[root@k8s-master ~]# kubectl get configmaps -n kube-system
NAME DATA AGE
calico-config 4 158d
coredns 1 159d
extension-apiserver-authentication 6 159d
kube-proxy 2 159d
kube-root-ca.crt 1 159d
kubeadm-config 2 159d
kubelet-config-1.20 1 159d
[root@k8s-master ~]# kubectl edit configmaps/kube-proxy -n kube-system
...
apiVersion: v1
data:config.conf: |-apiVersion: kubeproxy.config.k8s.io/v1alpha1bindAddress: 0.0.0.0
#找到mode字段,为空的话代表使用的是默认的代理模式(iptables),若想使用ipvs的话 直接将mode的字段值改为 "ipvs"
#mode: ""
mode: "ipvs"
3.重启要修改代理模式的kube-proxy pod
[root@k8s-master ~]# kubectl delete pod/kube-proxy-77bv7 -n kube-system
[root@k8s-master ~]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-proxy-5nthr 1/1 Running 0 159d 192.168.77.11 k8s-master <none> <none>
kube-proxy-hzh9m 1/1 Running 0 7m2s 192.168.77.14 k8s-node3 <none> <none>
kube-proxy-q4tjh 1/1 Running 0 159d 192.168.77.13 k8s-node2 <none> <none>
kube-proxy-v7s6z 1/1 Running 0 159d 192.168.77.12 k8s-node1 <none> <none>
4.再次查看重启过的kube-proxy是否已经切换成了ipvs代理模式
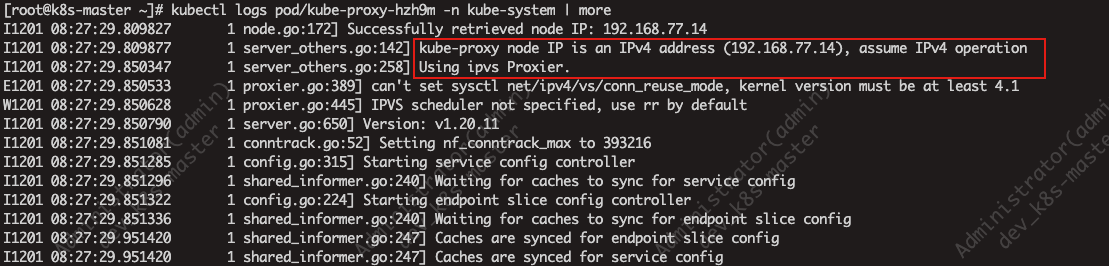
如果想让所有的节点都生效的话,需要重建所有节点的kube-proxy pod
二进制方式:
通过kube-proxy的日志来查看当前使用的代理模式

1.修改kube-proxy配置文件并重启kubelet
[root@k8s-node3 cfg]# vim kube-proxy-config.yml
...
#添加/修改
mode: ipvs
ipvs:scheduler: "rr"#注:配置文件路径根据实际安装目录为准[root@k8s-node3 cfg]# systemctl restart kube-proxy

2.验证ipvs代理模式的规则
上面我们也知道了验证ipvs规则需要使用 “ipvsadm -L -n” 命令
所以需要在kube-proxy pod所在的相应节点上安装ipvsadm来进行验证
[root@k8s-node3 ~]# yum -y install ipvsadm[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web3 NodePort 10.105.175.220 <none> 80:32306/TCP 25h
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7fbc4b76bd-2z8zn 1/1 Running 0 29h 10.244.36.74 k8s-node1 <none> <none>
web-7fbc4b76bd-8qfn8 1/1 Running 0 29h 10.244.36.67 k8s-node1 <none> <none>
web-7fbc4b76bd-xzxrf 1/1 Running 0 29h 10.244.36.92 k8s-node1 <none> <none>[root@k8s-node3 ~]# ipvsadm -L -n
#找到service对应的cluster ip 即可看到现在所使用的规则(非常清晰)
#NodePort流量入口
TCP 192.168.77.14:32306 rr-> 10.244.36.67:80 Masq 1 0 0 -> 10.244.36.74:80 Masq 1 0 0 -> 10.244.36.92:80 Masq 1 0 0 [root@k8s-node3 ~]# ipvsadm -L -n
#找到service对应的cluster ip 即可看到现在所使用的规则(非常清晰)
#Cluster IP流量入口
TCP 10.105.175.220:80 rr-> 10.244.36.67:80 Masq 1 0 0 -> 10.244.36.74:80 Masq 1 0 0 -> 10.244.36.92:80 Masq 1 0 0
七、service总体工作流程
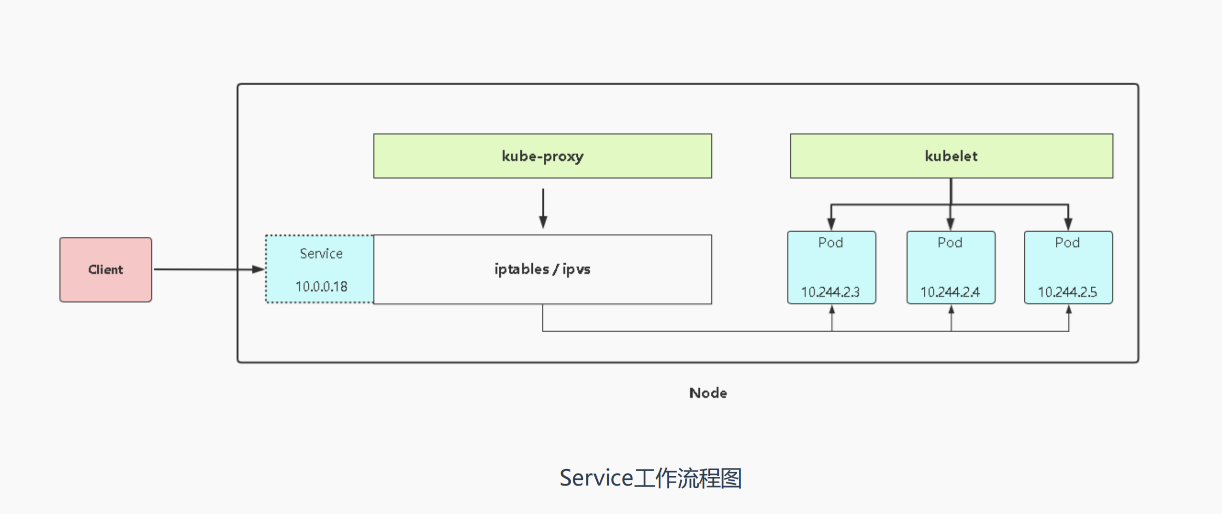
当客户端访问service时 实际是由iptables/ipvs来转发到后端的一组pod上,这些iptables/ipvs 转发的规则都是由kube-proxy进行管理维护的,它会根据你的工作模式来生成相应的规则;
八、kube-proxy ipvs和iptables的异同
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
- 与iptables相比,IPVS拥有以下明显优势:
- 为大型集群提供了更好的可扩展性和性能;
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- 支持服务器健康检查和连接重试等功能;
- 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。

九、Service DNS名称
service就类似于一个虚拟负载均衡器一样,而coredns就是为service进行解析的,它是一个DNS服务器,也是k8s默认使用的DNS,以Pod部署在集群中,CoreDNS服务监视Kubernetes API,为每一个Service创建DNS记录用于域名解析 这样我们就能在集群中使用servcie名称来访问service;
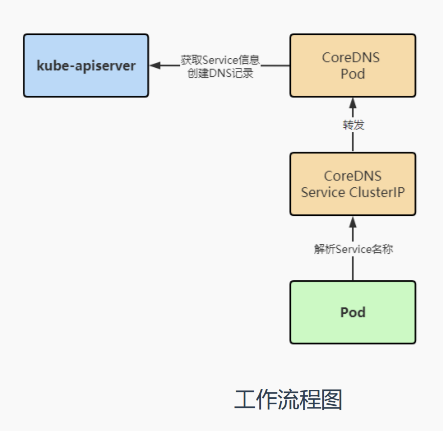
工作流程
在pod中解析service名称时,service名称会帮我们转发到coredns上,coredns会解析service名称并返回相对应的cluster ip,如果访问的是外部域名,那么会转到宿主机的dns上去处理,最后coredns是通过k8s api上去获取的service信息来创建的dns记录;
ClusterIP A记录格式:[service-name].[namespace-name].svc.cluster.local
示例:
my-service.my-namespace.svc.cluster.local
1.接下来创建一个pod来使用dns进行测试,看能不能通过名称来获取cluster ip
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 162d
web3 NodePort 10.105.175.220 <none> 80:32306/TCP 4d[root@k8s-master ~]# kubectl run bs --image=busybox:1.28.4 -- sleep 24h
pod/bs created
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
bs 0/1 Running 0 6s[root@k8s-master ~]# kubectl exec -it pod/bs /bin/sh
/ # nslookup web3.default.svc.cluster.local
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: web3.default.svc.cluster.local
Address 1: 10.105.175.220 web3.default.svc.cluster.local
#可以看到这里解析出的IP就是上面web3这个service的cluster ip/ # ping web3.default.svc.cluster.local
PING web3.default.svc.cluster.local (10.105.175.220): 56 data bytes
#使用ping命令也是可以解析到web3这个service的cluster ip 的/ # wget web3.default.svc.cluster.local
Connecting to web3.default.svc.cluster.local (10.105.175.220:80)
index.html 100% |*******************************************************************************************************************************************| 612 0:00:00 ETA
/ # cat index.html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>body {width: 35em;margin: 0 auto;font-family: Tahoma, Verdana, Arial, sans-serif;}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p><p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p>
</body>
</html>
#也可以使用curl命令根据servicename 来访问这个页面 或者使用wget命令根据servicename 来下载这个页面
2.接下来查看内部的dns是如何配置的
[root@k8s-master ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 81d
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 162d
.../ # cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
#可以看出这个IP就是 coredns服务器的IP,所以说集群内部所有的请求都会发送到coredns服务器上,它里面维护了service的dns记录 / # ping www.baidu.com
PING www.baidu.com (180.101.50.242): 56 data bytes
64 bytes from 180.101.50.242: seq=0 ttl=49 time=14.356 ms
64 bytes from 180.101.50.242: seq=1 ttl=49 time=14.250 ms
#coredns是不维护百度的域名记录的,它是有专门的dns服务器来维护的,所以如果访问的域名不在 "search" 范围之内,就会交给宿主机的dns进行处理,相当于coredns 代替了 宿主机的dns解析的外部域名;